Data Transformation has always been a tedious task for data processing engines. Distributed data processing engines can be very handy for processing very large datasets but it isn’t going to be competitive with running a single process on a single machine if the data fits in. Processing these small to medium sized datasets has been a problem with well known distributed data processing engines due to their initialization overheads. Keeping this in consideration, Photon targets empowering the user with a unique data transformation experience that is intelligent, productive, fast and efficient when working on small to medium sized datasets. First introduced at Strata in 2016, the latest developments in Photon create an enhanced experience for users.
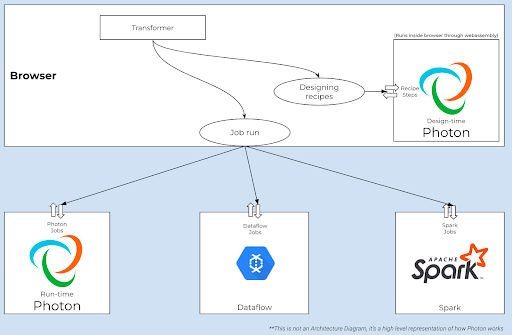
Photon is an in-memory, batch data processing engine, designed to be fast and efficient for small to medium-sized datasets due to minimal initialization overhead. When you build your recipe in the Designer Cloud, you can see the effects of the transformations that you are creating in real time. When you wish to produce result sets of these transformations, you must run a job, which performs a separate set of execution steps on the data. Photon snaps into this Intelligent Execution architecture of Designer Cloud to run side-by-side with more resource-intensive distributed computing frameworks like Apache Spark and Google Cloud Dataflow that Designer Cloud supports for big data processing.
Why do we need another execution engine?
We set two goals while designing Photon, firstly to provide real-time feedback to users as they try to transform their sample data in the browser, and secondly to create a fast and efficient environment for job execution on the complete dataset. As already mentioned, Designer Cloud leverages Google Dataflow and Apache Spark to process very large datasets efficiently in a distributed manner. For small to medium-sized data, Photon’s single node, in-memory architecture reduces the overhead during initialization significantly and makes it the optimal choice, allowing us to provide our users with reduced job execution times and costs. In our internal testing, Photon jobs were 85-95% faster than Google Dataflow Jobs. This lightweight design of Photon also allows us to embed Photon directly in the browser and power Designer Cloud’s real-time transformation UI, which many of our customers love.
How does Photon work?
Photon is Trifacta’s built-in interactive, data processing execution engine that runs on the web browser providing users real-time transformations for their datasets.
Photon takes the data transformation steps (also known as the Designer Cloud recipe), converts it into a Protobuf representation which is Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data. Further, it interprets the different transforms, prepares an execution graph, in which each node represents a transform to be applied on the Data.
The Data is then sent to each node in the form of multiple row batches (a continuous chunk of data) and the transform is applied on it, Execution is done in parallel by feeding it to the next node.

Photon leverages the above mechanism in 2 ways, one while designing the recipe step by step and the other is while running the entire recipe on a complete dataset.
While designing the recipe, Photon is built as a js module with help of the Emscripten toolchain that interacts with the UI. An individual recipe step is sent to Photon which checks if a corresponding result-table is present in the previously computed results in the “Photon cache” to avoid unnecessary computation. If not, it executes the recipe on the data shown in the UI, stores the results in the cache, and returns the results to the UI.
Photon also can run transformations on the whole dataset when it is chosen as an execution engine within Designer Cloud.

This uses a fully managed and scalable infrastructure Designer Cloud manages behind the scenes. Since Photon can be run as a standalone executable during job execution, it is easily containerized. This allows us to support Photon job execution directly in the user’s VPC, making job execution faster and more secure by bringing the execution engine to where the data resides.
In summary, Photon is ideal to process small and medium datasets with a faster and more efficient architecture, by overcoming the execution overhead that is typically observed by many mainstream processing engines. Users are provided with data transformation in real-time making it easy to use with Designer Cloud’s intuitive interface.
We would love for you to give it a spin today. Sign up for a free trial and experience the magic of Photon from Designer Cloud.